Ensemble averaging
In machine learning, particularly in the creation of artificial neural networks, ensemble averaging is the process of creating multiple models and combining them to produce a desired output, as opposed to creating just one model. Frequently an ensemble of models performs better than any individual model, because the various errors of the models "average out."
Contents |
Overview
Ensemble averaging is one of the simplest types of committee machines. Along with boosting, it is one of the two major types of static committee machines.[1] In contrast to standard network design in which many networks are generated but only one is kept, ensemble averaging keeps the less satisfactory networks around, but with less weight.[2] The theory of ensemble averaging relies on two properties of artificial neural networks:[3]
- In any network, the bias can be reduced at the cost of increased variance
- In a group of networks, the variance can be reduced at no cost to bias
Ensemble averaging creates a group of networks, each with low bias and high variance, then combines them to a new network with (hopefully) low bias and low variance. It is thus a resolution of the bias/variance dilemma.[4] The idea of combining experts has been traced back to Pierre-Simon Laplace.[5]
Method
The theory mentioned above gives an obvious strategy: create a set of experts with low bias and high variance, and then average them. Generally, what this means is to create a set of experts with varying parameters; frequently, these are the initial synaptic weights, although other factors (such as the learning rate, momentum etc.) may be varied as well. Some authors recommend against varying weight decay and early stopping.[3] The steps are therefore:
- Generate N experts, each with their own initial values. (Initial values are usually chosen randomly from a distribution.)
- Train each expert separately.
- Combine the experts and average their values.
Alternatively, domain knowledge may be used to generate several classes of experts. An expert from each class is trained, and then combined.
A more complex version of ensemble average views the final result not as a mere average of all the experts, but rather as a weighted sum. If each expert is 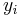 , than the overall result
, than the overall result 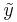 can be definied as:
can be definied as:
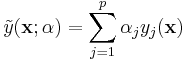
where 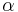 is a set of weights. The optimization problem of finding alpha is readily solved through neural networks, hence a "meta-network" where each "neuron" is in fact an entire neural network can be trained, and the synaptic weights of the final network is the weight applied to each expert. This is known as a linear combination of experts.[2]
is a set of weights. The optimization problem of finding alpha is readily solved through neural networks, hence a "meta-network" where each "neuron" is in fact an entire neural network can be trained, and the synaptic weights of the final network is the weight applied to each expert. This is known as a linear combination of experts.[2]
It can be seen that most forms of neural networks are some subset of a linear combination: the standard neural net (where only one expert is used) is simply a linear combination with all 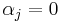 and one
and one 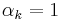 . A raw average is where all
. A raw average is where all 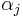 are equal to some constant value, namely one over the total number of experts.[2]
are equal to some constant value, namely one over the total number of experts.[2]
A more recent ensemble averaging method is negative correlation learning [6], proposed by Y. Liu and X. Yao. Now this method has been widely used in evolutionary computing.
Benefits
- The resulting committee is almost always less complex than a single network which would achieve the same level of performance[7]
- The resulting committee can be trained more easily on smaller input sets[1]
- The resulting committee often has improved performance over any single network[2]
- The risk of overfitting is lessened, as there are fewer parameters (weights) which need to be set[1]
References
- ^ a b c Haykin, Simon. Neural networks : a comprehensive foundation. 2nd ed. Upper Saddle River N.J.: Prentice Hall, 1999.
- ^ a b c d Hashem, S. "Optimal linear combinations of neural networks." Neural Networks 10, no. 4 (1997): 599–614.
- ^ a b Naftaly, U., N. Intrator, and D. Horn. "Optimal ensemble averaging of neural networks." Network: Computation in Neural Systems 8, no. 3 (1997): 283–296.
- ^ Geman, S., E. Bienenstock, and R. Doursat. "Neural networks and the bias/variance dilemma." Neural computation 4, no. 1 (1992): 1–58.
- ^ Clemen, R. T. "Combining forecasts: A review and annotated bibliography." International Journal of Forecasting 5, no. 4 (1989): 559–583.
- ^ Y. Liu and X. Yao, Ensemble Learning via Negative Correlation Neural Networks, Volume 12, Issue 10, December 1999, Pages 1399-1404
- ^ Pearlmutter, B. A., and R. Rosenfeld. "Chaitin–Kolmogorov complexity and generalization in neural networks." In Proceedings of the 1990 conference on Advances in neural information processing systems 3, 931. Morgan Kaufmann Publishers Inc., 1990.
- Perrone, M. P. (1993), Improving regression estimation: Averaging methods for variance reduction with extensions to general convex measure optimization
- Wolpert, D. H. (1992), "Stacked generalization", Neural networks 5 (2): 241–259
- Hashem, S. (1997), "Optimal linear combinations of neural networks", Neural Networks 10 (4): 599–614
- Hashem, S. and B. Schmeiser (1993), "Approximating a function and its derivatives using MSE-optimal linear combinations of trained feedforward neural networks", Proceedings of the Joint Conference on Neural Networks 87: 617–620